 第250325期 - Spark
第250325期 - Spark
5.9k star,很强!值得一试
假如你是一个程序员,需要一个高效且自然的语音合成工具,支持中英文语音生成,还能实现零样本语音克隆和可控语音生成,怎么办?不用担心,Spark-TTS正是为了解决这些需求而设计的!
Spark-TTS 简介
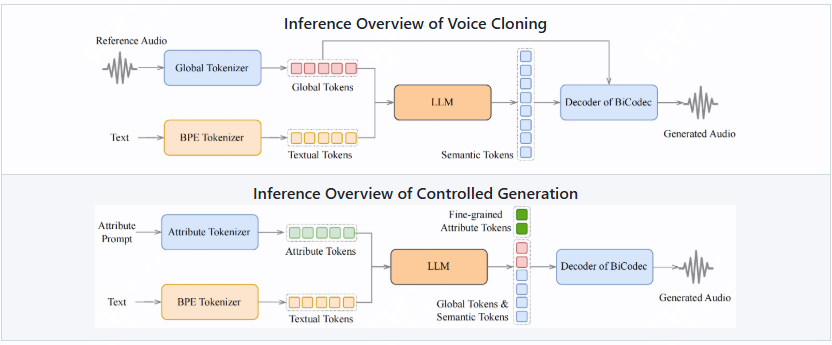
Spark-TTS 是一个基于大型语言模型 (LLM) 的高效文本转语音系统,能够生成自然且准确的语音合成效果。它适合研究人员和开发人员进行语音克隆、语音创建以及多语言语音处理。
功能特点
-
简单高效:
- Spark-TTS 完全基于 Qwen2.5,直接从语言模型预测的编码重构音频,无需额外的声学特征生成模型。
- 简化流程,提升效率并降低复杂性。
-
高质量语音克隆:
- 支持零样本语音克隆,可以在没有特定训练数据的情况下复制说话人的声音。
- 在跨语言和代码切换场景中无缝实现语音转换。
-
双语支持:
- 支持中文和英文语音生成,可跨语言合成自然准确的语音。
-
可控语音生成:
- 用户可以通过调整参数(如性别、音调和语速)来创建虚拟说话人。
如何开始
-
安装:
- 克隆仓库:
git clone https://github.com/SparkAudio/Spark-TTS.git - 设置运行环境:使用 Conda 创建环境并安装依赖项。
- 克隆仓库:
-
模型下载:
- 通过 Python 或 Git 克隆下载预训练模型。
-
运行示例:
- 使用命令行运行:执行
bash infer.sh或使用 Python 命令运行推理。 - 使用 Web UI 界面:运行
python webui.py --device 0启动用户界面,支持上传或录制音频进行语音克隆或语音创建。
- 使用命令行运行:执行
特殊方法与部署
Spark-TTS 还支持 Nvidia Triton 推理服务,利用 TensorRT-LLM 实现高效的推理性能,适用于生产环境部署。
Spark-TTS 不仅为程序员提供了一个强大的工具,还带来了高效与创新的语音合成解决方案。如果你对技术感兴趣或正在寻找语音处理领域的突破,Spark-TTS 是一个值得探索的选择!你觉得怎么样呢?