 第241128期 - victorialogs
第241128期 - victorialogs
开源日志工具,吊打elasticsearch?
今天看到VictoriaMetrics发布的victorialogs发布正式版,很早之前就有关注,而之前更多的是使用VictoriaMetrics作为prometheus的远程存储。
看了下ictorialogs的介绍,其中最感兴趣的是如下几条:
- 单节点可以提供足够的性能,官方给出的数据是elasticsearch或者loki的30倍(本文会单独写一篇文章介绍)
- 无需调优,系统会根据操作系统或者主机的cpu及mem来自动完成最佳适配
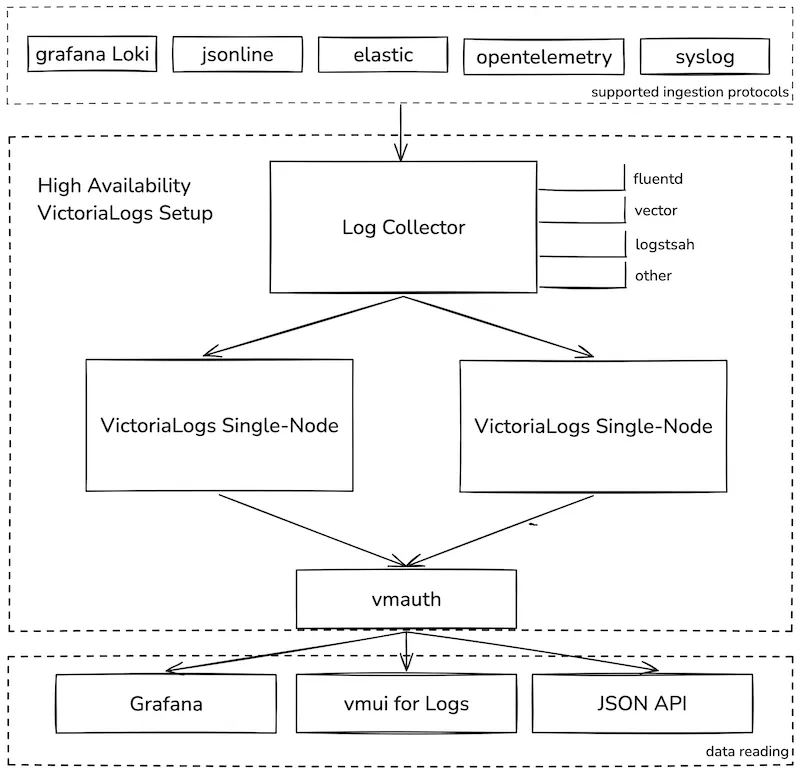
- 完美适配你目前用到的日志收集器如filebeat、Fluentbit、Fluentd等
当然了还有很多没有列出的特点,如与grpe、less、sort等命令适配、支持无序日志收集、支持命令行查询、支持告警等
有朋友就问了,那没有缺点嘛?
肯定是有的,完美的背后,肯定是要有所放弃的。
如它只支持单节点部署,目前没有集群版本,主要原因是单台性能足够,不过官方给出了高可用的双写方案,也有完善的备份恢复机制,不过对于日志收集来讲,这些也不是最重要的。
如何快速部署
你可以选择二进制方式或者docker方式部署
curl -L -O https://github.com/VictoriaMetrics/VictoriaMetrics/releases/download/v1.0.0-victorialogs/victoria-logs-linux-amd64-v1.0.0-victorialogs.tar.gz
tar xzf victoria-logs-linux-amd64-v1.0.0-victorialogs.tar.gz
./victoria-logs-prod
docker方式
docker run --rm -it -p 9428:9428 -v ./victoria-logs-data:/victoria-logs-data \
docker.io/victoriametrics/victoria-logs:v1.0.0-victorialogs
另外关于日志保留时间、大小及存储位置可以通过参数指定
-retentionPeriod=8w -retention.maxDiskSpaceUsageBytes=100GiB -storageDataPath=/var/lib/victoria-logs
监控方式
victorialogs 提供了支持prometheus方式的指标,如下:
http://localhost:9428/metrics
web ui
victorialogs提供了用于日志查询和探索的 Web UI http://localhost:9428/select/vmui
有三种显示查询结果的方式:
- group 结果显示为一个表格,其中的行按流字段分组
- table 以表的形式显示查询结果
- json 显示来自 /select/logsql/query HTTP API 的原始 JSON 响应
关于victorialogs的实现原理
为了更高效地处理和查询海量日志数据,VictoriaLogs 采取了一些独特的方法。
日志字段拆分与布隆过滤器
VictoriaLogs 会将每个日志字段拆分成多个词(即 tokens),类似于 Elasticsearch 的做法。然而,与 Elasticsearch 使用倒排索引不同,VictoriaLogs 使用布隆过滤器来处理这些 tokens。布隆过滤器的作用是快速跳过查询中不包含特定词的数据块。例如,当搜索某个唯一短语(如 trace_id=7d75e660–9fcf-4b6a-b860-210293b5eda6)时,大多数数据块会被直接跳过,只有少数数据块会被读取和检查,从而提高查询性能,特别是对于“大海捞针”类型的查询。
布隆过滤器只需要每个唯一 token 占用 2 字节,而 Elasticsearch 的倒排索引则需要至少 8 字节。由于唯一 token 的数量通常远小于总 token 数量,因此布隆过滤器的存储需求大约比倒排索引小 10 到 100 倍。这不仅减少了存储空间需求,还降低了数据摄取和查询时的内存占用,也减少了重查询期间的磁盘读取量。
日志流的概念
VictoriaLogs 还引入了类似 Loki 的日志流概念,但默认情况下不会将日志字段放入日志流标签集中。相反,它依赖日志运输器通过 _stream_fields 查询参数或 VL-Stream-Fields HTTP 请求头提供的一组流日志字段。这样可以高效地存储和查询具有高基数字段(如 user_id, trace_id 或 ip)的结构化日志。
列存储
VictoriaLogs 将每个日志字段的数据分组并存储在物理上独立的存储区域(类似于 ClickHouse 的列存储)。这极大地减少了查询过程中需要读取的数据量,因为只有所请求字段的数据会从存储中读取。此外,这种方式还能提高按字段压缩数据的比率,从而进一步减少存储空间需求。
综上所述
VictoriaLogs 通过使用布隆过滤器来提高全文搜索性能,同时保持低存储空间需求(最多比 Elasticsearch 少 15 倍)和低内存需求(最多比 Elasticsearch 少 30 倍)。虽然简单查询可能比 Elasticsearch 慢,但在处理包含多个过滤条件的复杂查询时,VictoriaLogs 通常表现优于 Elasticsearch。此外,VictoriaLogs 支持类似 Grafana Loki 的日志流,并使用列存储来进一步减少存储空间使用。这些特性使得 VictoriaLogs 成为处理和查询海量日志数据的高效工具。